
This is a guest post from Richard Rodger, CTO at nearForm & a leading Node.js specialist. He is a technology entrepreneur and wrote the seminal book on Node: Beginning Mobile Application Development in the Cloud. This is the first of a three-part blog, with the second to follow next week and the last post after his In The Brain talk at Skills Matter on the 22 September, building a Node.js search engine using the microservice architecture.
Richard will also be speaking at FullStack, the Node and JavaScript Conference on 23 October.
In this posts Richard will take us through his experience of building a search engine using microservices and how using a microservice architecture can be used to isolate features and create separate components that can be independently developed, deployed and maintained. Part one will introduce you to microservices and start you building your components and modules. Next week, we’ll cover testing the microservice!
Finding the right Node.js module is hard. With over 90,000 modules (and counting!) it can be tricky to pick the right one. You’ll often come across multiple modules that solve your problem. They are often incomplete, abandoned or just badly documented. It’s hard to make the right choice and you have to rely on rules of thumb. When was the last commit? How many stars? How credible is the author?
It would be great if there was a search engine for Node.js modules that ranked them using these heuristics. I built one in late 2012 that tried to do just that. It was a miserable failure! The quality of the results was pretty poor – see for yourself at nodezoo.com. Search engines are harder than they look, let me tell you. Recently I decided to try again. This time, I wanted to use a microservice architecture. This lets me iterate many aspects of the engine, so that it can get better over time.
This blog post is the first in a series covering nodezoo version 2.0. I’ll also be talking about this at my upcoming In The Brain talk on September 22nd. In this blog post you’ll see how a microservice architecture can be used to isolate the features of the search engine into separate components that can be independently developed, deployed, and maintained – developer heaven!
Let’s focus on the information page for each module. After you get your search results, you should be able to click-through to a page that shows you all the useful meta data about a module, such as the number of Github stars, so that you can compare it with other modules. So today we’ll build out one of the services needed to collect that information and display it.
Why Microservices?
The search engine will use a microservice architecture. Let’s take a closer look at what that means. Microservices are small, independently running processes. Instead of a single large, monolithic application running all your functionality, you break it apart into many separate pieces that communicate with each other over the network.
There are quite a few informal “definitions” of microservices out there:
…developing a single application as a suite of small services, each running in its own process and communicating with lightweight mechanisms, often an HTTP resource API
James Lewis & Martin Fowler…a system that is built up of small, lightweight services, where each performs a single function. The services are arranged in independently deployable groups and communicate with each other via a well defined interface and work together to provide business value.
David Morgantini…a simple application that sits around the 10-100 lines-of-code mark
James HughesAnd even a “ManifestNO”
Russell Miles
Of course, I have my own definition! It’s really the effect on humans that matters most. Microservices are just more fun. I prefer:
An independent component that can be rewritten in one week.
This gets to the heart of microservices. They are disposable code. You can throw away what you have and start again with very little impact. That makes it safe to experiment, safe to build up technical debt and safe to refactor.
What about all that network traffic, won’t it slow things down to a crawl? In practice, no. We’ve not seen this in the production systems that we have built. It comes down to two factors. First, inter-service communication grows logarithmically, not exponentially. Most services don’t need to talk to most other services.
Second, responding to any message has a relatively shallow dependency-based traversal of the service network. Huh? Microservices can work in parallel. Mostly they don’t need to wait for each other. Even when they do, there’s almost never a big traffic jam of services waiting in a chain.
In fact a microservice architecture has a very nice characteristic. Out-of-the-box you get capacity to handle lots and lots of users. You can scale easily by duplicating services which by design have no shared state. Yes, it does make each individual request a little slower. How bad! In contrast, traditional monolithic approaches give you the opposite: better performance for one user, terrible performance for many. Throughput is what counts if you want to have lots of users and microservices make a very cheap trade-off in terms of pure performance. Here’s the obligatory chart showing how this works. Hint: you want to be in the green box. The red one gets you fired.
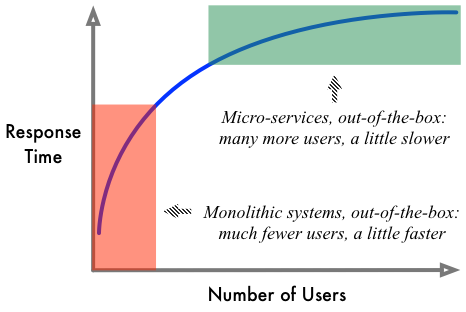
One more thing. It’s easy to accuse microservices of falling afoul of the Fallacies of Distributed Computing. Essentially pretending that the network is just like making a local function call. That’s precisely wrong. Microservices embrace the network. You are naturally led to deal with the effects of the network when you use microservices because you can’t avoid them. You have to assume that every time you talk to another component in the system you will incur network traffic. It enforces a productive discipline and clarity of mind. Architecture astronauts are quickly and severely punished.
The Search Engine
You won’t build a search engine in one blog post. Let’s look at the module information page. This collects data from multiple sources and displays it all together. Let’s take a bias towards the Availability aspect of the CAP Theorem. Whatever else happens, we want to display a web page to the user.
We’ll keep things simple. Each Node.js module has description data stored by the NPM registry. Let’s get a subset of that information and display it. Most Node.js modules also have a Github repository. It’s useful to know how many stars and forks a module has as that gives some measure of how good it is. Down the road, we might pull information from other sources, like the module author’s blog or a Google search.
So we have a set of information sources, mostly external, certainly unreliable, and definitely slow! Whatever else happens we’ve decided that we’ll always display the information page even if we have no information or only some of it. In microservice terms, you publish a message looking for information and you display whatever you get back within a certain time-frame (or some other cut-off condition). This scatter-gather pattern is explained in detail by Fred George in this video.
This acceptance of faulty behavior, this anticipation that hard choices will have to be made and results will be imperfect, is a key part of the microservice philosophy. We aim to reduce uncertainty and the frequency of failure but we never seek to eliminate it. Solutions which cannot tolerate component failure are inherently fragile. We aim to be anti-fragile.
The Architecture
There needs to be a microservice for the information page and then one for each data source. For the moment, that means one for NPM and one for Github. And we’ll also need a web server! Let’s use KrakenJS because it’s pretty cool and has easy server-side templates.
Let’s call the information page microservice nodezoo-info, the data source ones nodezoo-npm & nodezoo-github, and the KrakenJS process can be nodezoo-web. That gives you four Node.js processes to run at a minimum, or not – you’ll see in a later part of this series how to reduce this to one process when developing and debugging locally.
Now, the nodezoo-web service delivers the information page. Let’s use the URL path /info/MODULE. The controller that builds that page should ask the nodezoo-info service for the details of the module. The nodezoo-info service should publish a message to any interested services that care to provide information about modules. The nodezoo-npm and nodezoo-github services should listen for that message and respond if they can.
Sounds nice and neat, but there’s a complication. Isn’t there always! You need the Github repository URL to query Github. That information is in NPM. And yet, the Github service is not allowed to know about the NPM service. For the moment let’s assume we can have Schrödinger services that both do and do not know about other services. That allows the Github service to ask the NPM service for the repository URL. To be continued…
This is so simple that you don’t even need an architecture diagram to understand it. What? It would be “unprofessional” not to provide one you say? But microservice deployments are necessarily dynamic and fluid, changing minute-by-minute to meet the demands of user load and new business requirements. The whole point is that there is no Architecture (capital A). The best mental model is to suspend disbelief and assume all services can see all messages, ignoring those they don’t care about. Message transport is just an optimization problem.
Oh, all right then.
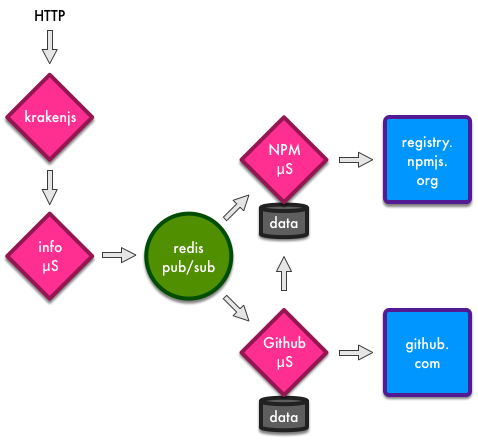
The lovely diagram shows you something else. Each microservice owns its own data. There is no shared database. What about consistency you say? Well think about our use case. Node.js modules are not updated that frequently. We can publish messages when they are, and any services that need to update, can do so at their own pace. But module data will be out-of-date and inconsistent in some cases! Well, shucks. That’s by design. We are not going for 100% here. We’re going for fault tolerance.
Think about the error level you find acceptable, and put remedial actions in place to achieve that. Perhaps you publish the update message multiple times over the following 24 hours. It’s wasteful of resources, but covers a lot of cases where services might be down temporarily. Perhaps you have a cross-check service that randomly samples the services to see how consistent they are. Perhaps you have a set of data services and you outsource the problem. This is the style of thinking you need to adopt. Assume things will break.
Now there are many use-cases where this cavalier approach to data is not going to fly. But there are many others where it is perfectly fine. Microservices make it easy to avoid over-engineering when you don’t have to. They can all talk to the same ACID-compliant Enterprise Database Solution if you really care that much. But then you have to install and maintain the damn thing. Expensive.
The Code
Let’s look at the NPM service first as that’s pretty simple. The code in this article uses the Seneca microservice framework. That means it’s concise, you can focus on the business logic, and you don’t need to worry about message transportation. Some may balk at the idea of using a framework for microservices. After three years of building systems this way, it makes sense for us to put our collected experience into a reusable package. But you don’t need permission to go bare bones if that’s what you want to do. The basic principles are exactly the same.
The NPM service needs to do three things:
- return data about a module, if it has that data;
- query the NPM registry for data about a module;
- extract relevant data from the large NPM JSON document returned for each module.
Seneca defines microservices as collections of one or more message patterns. If a message matches the pattern, then the microservice executes it. Messages are considered to be plain old JSON documents. The patterns are simple name and value pairs. If the JSON document has matching top-level properties, then it’s a match. More specific matches win. That is, a pattern with more name and value pairs beats a pattern with fewer. And that’s it.
The pattern matching is deliberately simple so that you can simulate it inside your own head. There is no fancy stuff like regular expressions or dot-notation for sub-properties. The Principle of Least Power is very – well – powerful. If you need to get fancy, match as much as you can and do the rest in code.
As noted above, all the code for this article is open-sourced in Github. It’s available under the MIT license, so you are free to re-use for your own projects, open-source or commercial.
Here’s the message action that extracts data from the NPM JSON document.
// excerpt from: nodezoo-npm/npm.js
seneca.add(
'role:npm,cmd:extract',
{
data: { required$:true, object$:true },
},
cmd_extract)
function cmd_extract( args, done ) {
var seneca = this
var data = args.data
var dist_tags = data['dist-tags'] || {}
var latest = ((data.versions||{})[dist_tags.latest]) || {}
var repository = latest.repository || {}
var out = {
name: data._id,
version: dist_tags.latest,
giturl: repository.url
}
done(null,out)
}
The message action pattern is role:npm, cmd:extract. This is completely arbitrary. The role property namespaces the pattern, and the cmd property names what it does. Not all patterns are commands, some are just announcements for general interest, as you’ll see in later parts.
The implementation of the pattern, the action that it triggers, is placed in the cmd_extract function. This is just good code organization. It also means you can list all the patterns at the top of the source code file, which gives you a little bit of built-in documentation.
The seneca.add method adds a new message pattern. You supply the pattern and its implementing function. Optionally you can specify the arguments you need. These are additional properties that should be present in the message JSON document. In this case, a data property must be present, and it’s value must be an object. That is, the data property should contain the the NPM JSON result. For more details of the argument validation format, see the parambulator Node.js module.
The action implementation follows the standard Node.js callback pattern:
function some_action( args, done ) {
// context-specific seneca instance – gives you nice logs!
var seneca = this
...
// there is no error, so the first argument is null
done(null,out)
}
The args object is the message document. This what you act on. The done function is the callback to call when you are finished. If there was an error, you should pass an Error object as the first argument to done. Otherwise, pass a null, and then your result as the second. Returning a result is not required. Some messages are fire-and-forget, and there is no result, as such. Always call done though, even if it’s just done(); as you need to signal that you’re finished processing.
The extraction logic is nothing special, it just picks values out of an object data structure. To see the full structure, try this for example.
Data Storage
Microservices do need to store data occasionally. If you want to be puritanical, then data storage should also be a microservice! Data operations are just more messages. A load message maybe, a save message, a remove message, and so forth. Purity is overrated. Seneca does do things this way, but it provides a nice and easy ActiveRecord-style interface for data entities, so you don’t have to worry about it.
This gives you all sorts of lovely side-benefits. Choose this database! No, that one! Change database in mid-project. Who cares! Need to cache data in redis or memcached? Intercept the messages! No need for the business logic code to know anything about it. Need special case validation or data munging? Intercept and do what you want!
I’ll stop now.
Here’s what the API looks like:
- Create a new data entity: var color = seneca.make$(“color”)
- Save some data: color.name = “red”; color.save$( callback )
- Load some data: color.load$( {name:”red”}, callback )
For more details, see the Seneca Data Entities documentation.
For the moment, you’ll store all data as plain text JSON files on disk. Yes, plain old JSON. On disk. No database needed. Later on, in production, we can worry about LevelDB or Mongo or Postgres (no code changes required! I promise). For now, let’s make local development and debugging super easy.
OK, let’s respond to a request for information about a Node.js module:
seneca.add(
'role:npm,cmd:get',
{
name: { required$:true, string$:true },
},
cmd_get)
function cmd_get( args, done ) {
var seneca = this
var npm_ent = seneca.make$('npm')
var npm_name = args.name
npm_ent.load$( npm_name, function(err,npm){
if( err ) return done(err);
// npm is not null! there was data! return it!
if( npm ) {
return done(null,npm);
}
// query the npmjs registry as we
// don't know about this module yet
else {
seneca.act(
'role:npm,cmd:query',
{name:npm_name},
done)
}
})
}
This implements the role:npm,cmd:get pattern. You need to provide a name property in your message. Speaking of which, here’s an example message that will work:
{
"role": "npm",
"cmd": "get",
"name": "express"
}
The code attempts to load a module description with the given name. The npm entity stores this data. If it is found, well then just return it! Job done. The caller gets back a JSON document with data fields as per the role:npm,cmd:extract action.
If the module was not found in the data store, then you need to query the NPM registry. Submit a new message with pattern role:npm,cmd:query. That’s that action that does that job. Return whatever it returns.
Finally, let’s look at the query action. This needs to make a HTTP call out the the registry.npmjs.org site to pull down the module JSON description. The best module to do this is request.
seneca.add(
'role:npm,cmd:query',
{
name: { required$:true, string$:true },
},
cmd_query)
function cmd_query( args, done ) {
var seneca = this
var npm_ent = seneca.make$('npm')
var npm_name = args.name
var url = options.registry+npm_name
request.get( url, function(err,res,body){
if(err) return done(err);
var data = JSON.parse(body)
seneca.act('role:npm,cmd:extract',{data:data},function(err,data){
if(err) return done(err)
npm_ent.load$(npm_name, function(err,npm){
if( err ) return done(err);
// already have this module
// update it with .data$ and then save with .save$
if( npm ) {
return npm.data$(data).save$(done);
}
// a new module! manually set the id, and then
// make a new unsaved entity with .make$,
// set the data and save
else {
data.id$ = npm_name
npm_ent.make$(data).save$(done);
}
})
})
})
}
This action constructs the query URL and performs a HTTP GET against it. The resulting document is then parsed by the role:npm,cmd:extract action to pull out the properties of interest and merged into any existing data on that module, or else saved as a new data entity. The data.id$ = npm_name line is where you manually set the identifier you want to use for a new data entity.
And that’s all this microservice does. 112 lines of code. Not bad.
Check back next week for part two, when we’ll cover testing the microservice. Can’t wait until then? Let us know your thoughts, ideas and experiences with microservices below, or give us a shout on Twitter!



 July is here and while the summer sun may be nowhere to be seen recently, Skills Matter is the hottest spot this side of Havana. Among the superstars coming to town next week is the infamous Robert C. Martin — known affectionately in the Agile world as “Uncle Bob”. Uncle Bob Martin will be delivering two expert training courses; his Software Craftmanship Clean Code workshop as well as his TDD and Refactoring course — as an added bonus, Uncle Bob is also giving an “In the Brain” seminar on the Last Programming Language. This seminar has been so popular we have had to close even the waiting list — but as with all our talks, it will be recorded and the Skillscast video available on the Skills Matter website the next day.
July is here and while the summer sun may be nowhere to be seen recently, Skills Matter is the hottest spot this side of Havana. Among the superstars coming to town next week is the infamous Robert C. Martin — known affectionately in the Agile world as “Uncle Bob”. Uncle Bob Martin will be delivering two expert training courses; his Software Craftmanship Clean Code workshop as well as his TDD and Refactoring course — as an added bonus, Uncle Bob is also giving an “In the Brain” seminar on the Last Programming Language. This seminar has been so popular we have had to close even the waiting list — but as with all our talks, it will be recorded and the Skillscast video available on the Skills Matter website the next day. ral and “JavaServer Faces in Action” author Kito Mann giving a free talk on Polyglot Java Server Faces (a must for anyone with an interest in JSF and Java, Scala, Groovy or Ruby) as well as expert training in acclaimed JSF2 in Action.
ral and “JavaServer Faces in Action” author Kito Mann giving a free talk on Polyglot Java Server Faces (a must for anyone with an interest in JSF and Java, Scala, Groovy or Ruby) as well as expert training in acclaimed JSF2 in Action. Just when you think Skills Matter must surely burst at the seams with all this going on, we are hosting CDI Europe’s “Apps for Good” Dragon’s Den event, where teams of Apps for Good students will present their final app ideas to a panel of high profile industry professionals. Apps for Good work with young people, helping them to create mobile and web apps that make their world better, focusing on solving real life issues that matter to them and their community. At Skills Matter, we can’t speak highly enough of the work Apps for Good do — and encourage everyone to
Just when you think Skills Matter must surely burst at the seams with all this going on, we are hosting CDI Europe’s “Apps for Good” Dragon’s Den event, where teams of Apps for Good students will present their final app ideas to a panel of high profile industry professionals. Apps for Good work with young people, helping them to create mobile and web apps that make their world better, focusing on solving real life issues that matter to them and their community. At Skills Matter, we can’t speak highly enough of the work Apps for Good do — and encourage everyone to 